Latest Blog Posts
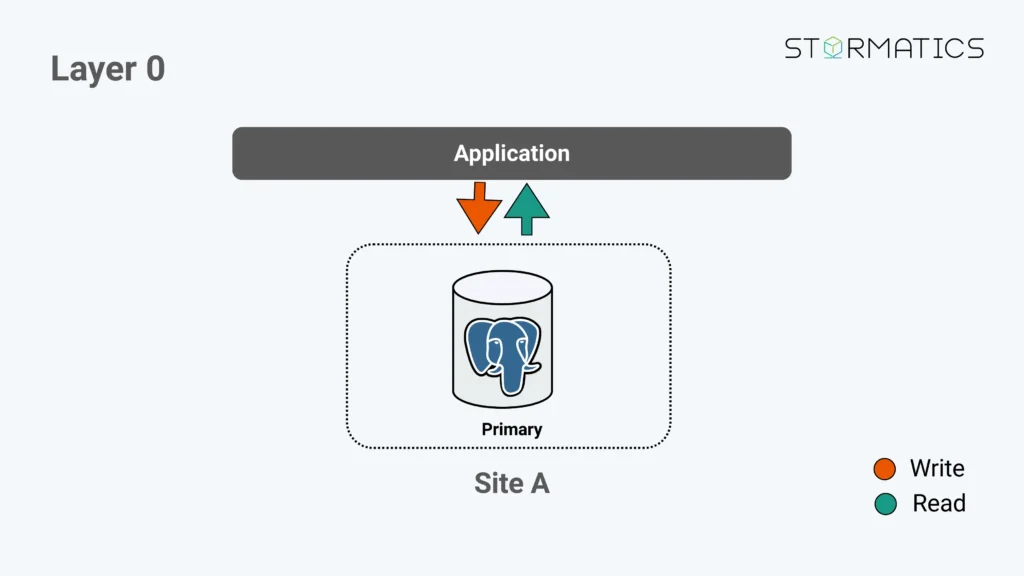
Thinking of PostgreSQL High Availability as Layers
Posted by Umair Shahid in Stormatics on 2026-03-09 at 14:03
Contributions for week 9, 2026
Posted by Cornelia Biacsics in postgres-contrib.org on 2026-03-09 at 10:31
The community met on Wednesday, March 4, 2026 for the 7. PostgreSQL User Group NRW MeetUp (Cologne, ORDIX AG). It was organised by Dirk Krautschick and Andreas Baier.
Speakers:
- Robin Riel
- Jan Karremans
PostgreSQL Berlin March 2026 Meetup took place on March 5, 2026 organized by Andreas Scherbaum and Sergey Dudoladov.
Speakers:
- Andreas Scherbaum
- Tudor Golubenco
- Narendra Tawar
- Kai Wagner
Kai Wagner wrote about his experience at the meetup PostgreSQL Berlin Meetup - March 2026
Andreas Scherbaum wrote a blog posting about the Meetup.
SCALE 23x (March 5-8, 2026) had a dedicated PostgreSQL track, filled by the following contributions
Trainings:
- Elizabeth Christensen
- Devrim Gunduz
- Ryan Booz
Talks:
- Nick Meyer
- Tristan Ahmadi
- Alexandra Wang
- Christophe Pettus
- Max Englander
- Magnus Hagander
- Bruce Momjian
- Robert Treat
- Payal Singh
- German Eichberger
- Jimmy Angelakos
- Justin Frye
SCALE 23x PostgreSQL Booth volunteers:
- Bruce Momjian
- Christine Momjian
- Gabrielle Roth
- Jennifer Scheuerell
- Magnus Hagander
- Devrim Gunduz
- Elizabeth Garret Christensen
- Robert Treat
- Pavlo Golub
- Phill Vacca
- Jimmy Angelakos
- Erika Miller
- Aya Griswold
- Alex Wood
- Donald Wong
- Derya Gumustel
AI Features in pgAdmin: Configuration and Reports
Posted by Dave Page in pgEdge on 2026-03-09 at 05:31
This is the first in a series of three blog posts covering the new AI functionality coming in pgAdmin 4. In this post, I'll walk through how to configure the LLM integration and introduce the AI-powered analysis reports; in the second, I'll cover the AI Chat agent in the query tool; and in the third, I'll explore the AI Insights feature for EXPLAIN plan analysis.Anyone who manages PostgreSQL databases in a professional capacity knows that keeping on top of security, performance, and schema design is an ongoing endeavour. You might have a checklist of things to review, or perhaps you rely on experience and intuition to spot potential issues, but it is all too easy for something to slip through the cracks, especially as databases grow in complexity. We've been thinking about how AI could help with this, and I'm pleased to introduce a suite of AI-powered features in pgAdmin 4 that bring large language model analysis directly into the tool you already use every day.
Configuring the LLM Integration
Before any of the AI features can be used, you'll need to configure an LLM provider. pgAdmin supports four providers out of the box, giving you flexibility to choose between cloud-hosted models and locally-running alternatives:- Anthropic
- (Claude models)
- OpenAI
- (GPT models)
- Ollama
- (locally-hosted open-source models)
- Docker Model Runner
- (built into Docker Desktop 4.40 and later)
Server Configuration
At the server level, there is a master switch in (or, more typically, ) that controls whether AI features are available at all:When is set to , all AI functionality is hidden from users and cannot be enabled through preferences. This gives administrators full control over whether AI features are permitted in their environment, which is particularly important in organisations with strict data governance policies.Below the master switch, you'll find default configuration for each provider:For the cloud providers (Anthropic and OpenAI), API keys are read from files on di[...]Production Query Plans Without Production Data
Posted by Radim Marek on 2026-03-08 at 21:15
In the previous article we covered how the PostgreSQL planner reads pg_class and pg_statistic to estimate row counts, choose join strategies, and decide whether an index scan is worth it. The message was clear: when statistics are wrong, everything else goes with it.
PostgreSQL 18 changed that. Two new functions: pg_restore_relation_stats and pg_restore_attribute_stats write numbers directly into the catalog tables. Combined with pg_dump --statistics-only, you can treat optimizer statistics as a deployable artifact. Compact, portable, plain SQL.
The feature was driven by the upgrade use case. In the past, major version upgrades used to leave pg_statistic empty, forcing you to run ANALYZE. Which might take hours on large clusters. With PostgreSQL 18 upgrades now transfer statistics automatically. But that's just the beginning. The same logic lets you export statistics from production and inject them anywhere - test database, local debugging, or as part of CI pipelines.
The problem
Your CI database has 1,000 rows. Production has 50 million. The planner makes completely different decisions for each. Running EXPLAIN in CI tells you nothing about the production plan. This is the core premise behind RegreSQL. Catching query plan regressions in CI is far more reliable when the planner sees production-scale statistics.
Same applies to debugging. A query is slow in production and you want to reproduce the plan locally, but your database has different statistics, and planner chooses the predictable path. Porting production stats can provide you that snapshot of thinking planner has to do in production, without actually going to production.
pg_restore_relation_stats
The first of functi
[...]New Presentation
Posted by Bruce Momjian in EDB on 2026-03-07 at 18:45
I just gave a new presentation at SCALE titled The Wonderful World of WAL. I am excited to have a second new talk this year. (I have one more queued up.)
I have always wanted to do a presentation about the write-ahead log (WAL) but I was worried there was not enough content for a full talk. As more features were added to Postgres that relied on the WAL, the talk became more feasible, and at 103 slides, maybe I waited too long. 
I had a full hour to give the talk at SCALE, and that was helpful. I was able to answer many questions during the talk, and that was important — many of the later features rely on earlier ones, e.g., point-in-time recovery (PITR) relies heavily on crash recovery, and if you don't understand how crash recovery works, you can't understand PITR. By taking questions at the end of each section, I could be sure everyone understood. The questions showed that the audience of 46 understood the concepts because they were asking about the same issues we dealt with in designing the features:
- How does server start know if crash recovery is needed?
- Can dirty shared buffers be written to storage before the WAL for the transaction that dirtied them is written?
- Can the WAL and heap/index storage get out of sync?
- How is the needed WAL accurately retained for replica servers?
- Can logical replicas be used as failover servers?
From proposal to PR: how to contribute to the new CloudNativePG extensions project
Posted by Gabriele Bartolini in EDB on 2026-03-07 at 06:36
In this article I walk you through the journey of adding the pg_crash extension to the new CloudNativePG extensions project. It explores the transition from legacy standalone repositories to a unified, Dagger-powered build system designed for PostgreSQL 18 and beyond. By focusing on the Image Volume feature and minimal operand images, the post provides a step-by-step guide for community members to contribute and maintain their own extensions within the CloudNativePG ecosystem.
Using Patroni to Build a Highly Available Postgres Cluster—Part 1: etcd
Posted by Shaun Thomas in pgEdge on 2026-03-06 at 07:48
The last PG Phriday article focused on the architecture of a Patroni cluster—the how and why of the design. This time around, it’s all about actually building one. I’ve often heard that operating Postgres can be intimidating, and Patroni is on a level above that. Well, I won’t argue on the second count, but I can try to at least ease some of the pain.To avoid an overwhelming deluge consisting of twenty pages of instructions, I’ve split this article into a series of three along these lines:
- Etcd
- Postgres and Patroni
- HAProxy
Why etcd?
The last article should have made it abundantly clear that the DCS is the nexus of communication and status for the whole cluster. As a result, it’s important to install it first and certify that it’s operational. Etcd is the default and the example most often deployed in Patroni clusters. It’s also the key/value storage system Kubernetes uses as a default, so it should be reliable enough for our needs.Don’t forget to keep a browser tab opened to the etcd documentation handy.What you’ll need
If you want to follow along with this demonstration, you’ll need:- The ability to create three VMs. Whether it’s
- Amazon EC2
- instances,
- Microsoft Hyper-V
- ,
- Xen
- ,
- QEMU
- ,
- Proxmox
- ,
- Oracle VirtualBox
- , or even
- VMWare Fusion
- , make sure you have a hypervisor and know how to use it.
- Three VMs running
- Debian Stable
- version 13. At the time of writing, this should be the Trixie release.
- SSH access as a root-capable user on each VM.
- An internet connection. If you have the first three, it’s likely you have this as well.
PostgreSQL Berlin March 2026 Meetup
Posted by Andreas Scherbaum on 2026-03-05 at 22:00
Inside the Kernel: The Complete Path to PostgreSQL Delete Recovery — From FPW to Data Resurrection
Posted by Zhang Chen on 2026-03-05 at 00:00
Expert-Level PostgreSQL Deleted Data Recovery in Just 5 Steps — No Kernel Knowledge Required
Posted by Zhang Chen on 2026-03-05 at 00:00
pg_plan_advice: Plan Stability and User Planner Control for PostgreSQL?
Posted by Robert Haas in EDB on 2026-03-04 at 17:55
I'm proposing a very ambitious patch set for PostgreSQL 19. Only time will tell whether it ends up in the release, but I can't resist using this space to give you a short demonstration of what it can do. The patch set introduces three new contrib modules, currently called pg_plan_advice, pg_collect_advice, and pg_stash_advice.
Read more »pg_plan_alternatives: Tracing PostgreSQL’s Query Plan Alternatives using eBPF
Posted by Jan Kristof Nidzwetzki on 2026-03-04 at 00:00
PostgreSQL uses a cost-based optimizer (CBO) to determine the best execution plan for a given query. The optimizer considers multiple alternative plans during the planning phase. Using the EXPLAIN command, a user can only inspect the chosen plan, but not the alternatives that were considered. To address this gap, I developed pg_plan_alternatives, a tool that uses eBPF to instrument the PostgreSQL optimizer and trace all alternative plans and their costs that were considered during the planning phase. This information helps the user understand the optimizer’s decision-making process and tune system parameters. This article explains how pg_plan_alternatives works, provides examples, and discusses the insights the tool can provide.
Cost-Based Optimization
SQL is a declarative language, which means that users only specify what they want to achieve, but not how to achieve it. For example, should the query SELECT * FROM mytable WHERE age > 50; perform a full table scan and apply a filter, or should it use an index (see the following blog post for more details about this)? The optimizer of the database management system is responsible for determining the best execution plan to execute a given query. During query planning, the optimizer generates multiple alternative plans. Many DBMSs perform cost-based optimization, where each plan is qualified with a cost estimate, a numerical value representing the estimated resource usage (e.g., CPU time, I/O operations) required to execute the plan. The optimizer then selects the plan with the lowest estimated cost as the final execution plan for the query.
To calculate the costs of the plan nodes, the optimizer uses a cost model that accounts for factors such as the number of rows predicted to be processed (based on statistics and selectivity estimates) and constants.
Query Plans in PostgreSQL
Using the EXPLAIN command in PostgreSQL, you can see the final chosen plan and its estimated total cost, and the costs of the individual plan nodes. For example, using
Mostly Dead is Slightly Alive: Killing Zombie Sessions
Posted by Lætitia AVROT on 2026-03-04 at 00:00
pg_semantic_cache in Production: Tags, Eviction, Monitoring, and Python Integration
Posted by Muhammad Aqeel in pgEdge on 2026-03-03 at 04:20
Part 2 of the Semantic Caching in PostgreSQL series that’ll take you from a working demo to a production-ready system.
From Demo to Production
In Part 1, we set up pg_semantic_cache in a Docker container and demonstrated how semantic similarity matching works. In summary, semantic caching associates a string with each query that allows us to search the cache by meaning instead of by the exact query text. We demonstrated a cache hit at 99.9% similarity and a cache miss at 68% (configurable defaults), and discussed why this can make a difference for LLM-powered applications.Now let's make it production-ready. A cache that can store and retrieve is useful, but a cache you can organize, monitor, evict, and integrate into your application is what you actually need for a production deployment. In this post, we'll cover all of that.We'll continue using the same Docker environment from Part 1. If you need to set it up again, refer to the Dockerfile and setup instructions in that post.Organizing with Tags
Tags let you group and manage cache entries by category; the at the end of the cache entry contains the tags associated with a specific query. For example, tags in our first query:Identify the query as being associated with and .In our second query, the tags identify the query as being associated with and :We can view the tags with the following statement:When the underlying data changes in our backing database, we can then use the tags to Invalidate old content in our data set:Eviction Strategies
Caches need boundaries. You can use those boundaries to keep data sets fresh:pg_semantic_cache provides eviction strategies you can use to set those boundaries for your cache:For easy maintenance in a production environment, you can schedule automatic cache clean up with pg_cron:Monitoring
The extension provides built-in views for observability. The semantic_cache.cache_health view provides an overview of the number of entries and use of a given cache:The semantic_cache.recent_cache_activity view provide[...]INSERT ... ON CONFLICT ... DO SELECT: a new feature in PostgreSQL v19
Posted by Laurenz Albe in Cybertec on 2026-03-03 at 04:00

© Laurenz Albe 2026
PostgreSQL has supported the (non-standard) ON CONFLICT clause for the INSERT statement since version 9.5. In v19, commit 88327092ff added ON CONFLICT ... DO SELECT. A good opportunity to review the benefits of ON CONFLICT and to see how the new variant DO SELECT can be useful!
What is INSERT ... ON CONFLICT?
INSERT ... ON CONFLICT is the PostgreSQL implementation of something known as “upsert”: you want to insert data into a table, but if there is already a conflicting row in the table, you want to either leave the existing row alone or update update it instead. You can achieve the former by using “ON CONFLICT DO NOTHING”. To update the conflicting row, you use “ON CONFLICT ... DO UPDATE SET ...”. Note that with the latter syntax, you must specify a “conflict target”: either a constraint or a unique index, against which PostgreSQL tests the conflict.
You may wonder why PostgreSQL has special syntax for this upsert. After all, the SQL standard has a MERGE statement that seems to cover the same functionality. True, PostgreSQL didn't support MERGE until v15, but that's hardly enough reason to introduce new, non-standard syntax. The real reason is that “INSERT ... ON CONFLICT”, different from “MERGE”, does not have a race condition: even with concurrent data modification going on, “INSERT ... ON CONFLICT ... DO UPDATE” guarantees that either an INSERT or an UPDATE will happen. There cannot be a failure because — say — a concurrent transaction deleted a conflicting row between our attempt to insert and to update that row.
An example that shows the race condition with MATCH
Create a table as follows:
CREATE TABLE tab (key integer PRIMARY KEY, value integer);
Then start a transaction and insert a row:
BEGIN; INSERT INTO tab VALUES (1, 1);
In a concurrent session, run a MERGE statement:
MERGE INTO tab USING (SELECT 1 AS key, 2 AS value) AS source ON source.key = tab.key WHEN MATCHED THEN UPDATE SET value = source.value WHEN NOT MATCHED THEN INSERT VALUES (so[...]
Contributions for week 8, 2026
Posted by Cornelia Biacsics in postgres-contrib.org on 2026-03-02 at 14:20
Prague PostgreSQL Meetup met on Monday, February 23 for the February Edition - organized by Gulcin Yildirim Jelinek & Mayur B.
Speakers:
- Damir Bulic
- Mayur B.
- Radim Marek
- Josef Šimánek
On Wednesday, February 25 2026 Raphael Salguero & Borys Neselovskyi delivered a talk at DOAG DBTalk Database: Operating PostgreSQL with high availability
On Thursday, 26 February, the 1st PgGreece Meetup happened - it was organized by Charis Charalampidi.
Speakers:
- Charis Charalampidi
- Eftychia Kitsou
- Florents Tselai
- Panagiotis Stathopoulos
The POSETTE 2026 Call for Paper Committee met to finalize and published the schedule :
- Claire Giordano
- Daniel Gustafsson
- Krishnakumar “KK” Ravi
- Melanie Plageman
PGConf.de 2026 Call for Paper Committee met to finalize and publish the schedule:
- Christoph Berg
- Josef Machytka
- Olga Kramer
- Polina Bungina
- Priyanka Chatterjee
pgdsat version 2.0
Posted by Gilles Darold in HexaCluster on 2026-03-01 at 04:04
Developer U: Exercising Cohesion and Technical Skill in PostgreSQL
Posted by Floor Drees in EDB on 2026-02-27 at 17:04
Open Source, Open Nerves
Posted by Vibhor Kumar on 2026-02-27 at 10:22
Trust, Governance, Talent, and the Enterprise Reality of PostgreSQL

Last year at the CIO Summit Mumbai, I had the opportunity to participate in a leadership roundtable with CIOs across banking, fintech, telecom, manufacturing, and digital enterprises.
The session was not a product showcase.
It wasn’t a benchmarking debate.
It wasn’t even primarily about technology.
It was about risk.
Specifically, the evolving role of open source — and particularly PostgreSQL — inside mission-critical enterprise environments.
Over the past week, I revisited those conversations in a LinkedIn series titled “Open Source, Open Nerves.” This blog expands on that series, capturing the deeper strategic undercurrents that surfaced in that room — and why they matter even more today.
The Evolution of the Conversation
There was a time when open source debates revolved around performance and cost. That time has passed.
PostgreSQL has proven itself across:
- Core banking workloads
- Telecom billing engines
- Financial risk platforms
- Regulatory reporting systems
- AI-driven analytics platforms
- Hybrid and multi-cloud architectures
No one in the room questioned whether PostgreSQL could handle enterprise-grade workloads.
The real conversation had shifted.
From capability
to accountability.
1. Trust Is the Real Architecture
One recurring sentiment defined the tone of the discussion:
“Power is no longer the question. Trust is.”
CIOs are not evaluating features in isolation. They are evaluating consequences.
When PostgreSQL becomes the backbone of a regulated enterprise system, the stakes include:
- Revenue continuity
- Regulatory exposure
- Customer trust
- Brand reputation
- Executive accountability
Trust in this context has multiple dimensions:
Operational Trust
Will it stay up under stress?
Will failover behave as designed?
Will replication hold during peak load?
Security Trust
Is the
[...]How Patroni Brings High Availability to Postgres
Posted by Shaun Thomas in pgEdge on 2026-02-27 at 05:33
Let’s face it, there are a multitude of High Availability tools for managing Postgres clusters. This landscape evolved over a period of decades to reach its current state, and there’s a lot of confusion in the community as a result. Whether it’s Reddit, the Postgres mailing lists, Slack, Discord, IRC, conference talks, or any number of venues, one of the most frequent questions I encounter is: How do I make Postgres HA?My answer has been a steadfast “Just use Patroni,” since about 2017. Unless something miraculous happens in the Postgres ecosystem, that answer is very unlikely to change. But why? What makes Patroni the “final answer” when it comes to Postgres and high availability? It has a lot to do with how Patroni does its job, and that’s what we’ll be exploring in this article.
The elephant in the room
By itself, Postgres is not a cluster in the sense most people visualize. They may envision a sophisticated mass of interconnected servers, furiously blinking their lights at each other, aware of each computation the others make, ready to take over should one fail. In reality, the “official” use of the word “cluster” in the Postgres world is just one or more databases associated with a single Postgres instance. It’s right in the documentation for Creating a Database Cluster.“A database cluster is a collection of databases that is managed by a single instance of a running database server.”The concept of multiple such instances interacting is so alien to Postgres that it didn’t even exist until version 9.0 introduced Hot Standbys and streaming replication back in 2010. And how do hot standby instances work? The same way as the primary node: they apply WAL pages to the backend heap files. Those WAL pages may be supplied from archived WAL files or by streaming them from the primary itself, but it’s still just continuous crash recovery by another name.This matters because each Postgres node still knows little to nothing about other nodes in this makeshift cluster over 15 years later. This isn’t necessarily a p[...]PostgreSQL Statistics: Why queries run slow
Posted by Radim Marek on 2026-02-26 at 23:01
Every query starts with a plan. Every slow query probably starts with a bad one. And more often than not, the statistics are to blame. But how does it really work? PostgreSQL doesn't run the query to find out — it estimates the cost. It reads pre-computed data from pg_class and pg_statistic and does the maths to figure out the cheapest path to your data.
In ideal scenario, the numbers read are accurate, and you get the plan you expect. But when they are stale, the situation gets out of control. Planner estimates 500 rows, plans a nested loop, and hits 25,000. What seemed as optimal plan turns into a cascading failure.
How do statistics get stale? It can be either bulk load, a schema migration, faster-than-expected growth, or simply VACUUM not keeping up. Whatever the cause, the result is the same. The planner is flying blind. Choosing paths based on reality that no longer exists.
In this post we will go inside the two catalogs the planner depends on, understand what ANALYZE actually gets for you from a 30,000-row table, and see how those numbers determine whether your query takes milliseconds or minutes.
Sample schema
For demonstration purposes we will use the same schema as in the article Reading Buffer statistics in EXPLAIN output.
CREATE TABLE customers (
id integer GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
name text NOT NULL
);
CREATE TABLE orders (
id integer GENERATED ALWAYS AS IDENTITY PRIMARY KEY,
customer_id integer NOT NULL REFERENCES customers(id),
amount numeric(10,2) NOT NULL,
status text NOT NULL DEFAULT 'pending',
note text,
created_at date NOT NULL DEFAULT CURRENT_DATE
);
INSERT INTO customers (name)
SELECT 'Customer ' || i
FROM generate_series(1, 2000) AS i;
INSERT INTO orders (customer_id, amount, status, note, created_at)
SELECT
(random() * 1999 + 1)::int,
(random() * 500 + 5)::numeric(10,2),
(ARRAY['pending','shipped','delivered','cancelled'])[floor(random()*4+1)::int],
CASE WHEN random() < 0.3 THEN 'Some note text hereA reponsible role for AI in Open Source projects?
Posted by Alastair Turner in Percona on 2026-02-26 at 14:00
AI-driven pressure on open source maintainers, reviewers and, even, contributors, has been very much in the news lately. Nobody needs another set of edited highlights on the theme from me. For a Postgres-specific view, and insight on how low quality AI outputs affect contributors, Tomas Vondra published a great post on his blog recently, which referenced an interesting talk by Robert Haas at PGConf.dev in Montreal last year. I won’t rehash the content here, they’re both quite quick reads and well worth the time.
The real cost of random I/O
Posted by Tomas Vondra on 2026-02-26 at 13:00
The random_page_cost was introduced ~25 years ago, and since the very beginning it’s set to 4.0 by default. The storage changed a lot since then, and so did the Postgres code. It’s likely the default does not quite match the reality. But what value should you use instead? Flash storage is much better at handling random I/O, so maybe you should reduce the default? Some places go as far as recommending setting it to 1.0, same as seq_page_cost. Is this intuition right?
Postgres JSONB Columns and TOAST: A Performance Guide
Posted by Paul Ramsey in Crunchy Data on 2026-02-25 at 15:05
Postgres has a big range of user-facing features that work across many different use cases — with complex abstraction under the hood.
Working with APIs and arrays in the jsonb type has become increasingly popular recently, and storing pieces of application data using jsonb has become a common design pattern.
But why shred a JSON object into rows and columns and then rehydrate it later to send it back to the client?
The answer is efficiency. Postgres is most efficient when working with rows and columns, and hiding data structure inside JSON makes it difficult for the engine to go as fast as it might.
JSONB in Postgres
How does JSON work in a database like Postgres that is optimized for rows and columns?
Like the text, bytea and geometry types, the jsonb type is "variable length" — there is no limit to how big it can be.
Under the covers, the PostgreSQL database stores all data in fixed-size 8-KB pages. But how can a data type with no size limit, like jsonb, exist in a database with such a small fixed storage size limit?
It does this by using The Oversize Attribute Storage Technique, aka "TOAST."
Ordinarily, all the attributes in a row can fit inside a page.
But sometimes, one or more of the attributes are too big to fit.
Under the covers, PostgreSQL quietly cuts up the big attributes, puts them in a side table and replaces them in the original page with a unique identifier.
So even for large attributes, the user does not have to do anything special to store them. The database abstraction remains intact. Or does it?
JSONB column types are convenient, but are they fast?
We are going to test JSONB performance for differently sized documents. The function generate_item_json will generate a jsonb object of arbitrary size.
The item_description can be expanded to make the object too big to fit on a page. This example generates a JSON object with a 40-byte description.
Here we create a 10,000-row table with four columns, a key, a name and price, and the o
[...]February Meetup: slides and recording are available!
Posted by Henrietta Dombrovskaya on 2026-02-25 at 11:30
Thank you, Shaun, for presenting, and huge thanks to all participants for an engaging and productive discussion!
As always, I am glad that people from all over the world can join us virtually, but if you are local, consider coming next time! We have pizza, and you can’t consume it virtually!
Semantic Caching in PostgreSQL: A Hands-On Guide to pg_semantic_cache
Posted by Muhammad Aqeel in pgEdge on 2026-02-25 at 06:03
Your LLM application is probably answering the same question dozens of times a day. It just doesn't realize it because the words are different each time.
The Problem with Exact-Match Caching
If you're running an AI-powered application like a chatbot, a RAG pipeline, an analytics assistant, or others, you've likely added a cache to cut down on expensive LLM calls. Most caches work by matching the exact query string. Same string, cache hit. Different string, cache miss.The trouble is that humans don't repeat themselves verbatim. These three queries all want the same answer:A traditional cache sees three unique strings and triggers three separate LLM calls. In production AI applications, research shows that 40-70% of all queries are semantic duplicates: different words, same intent. That translates directly into wasted API calls, wasted latency, and a bloated cloud bill.Semantic caching fixes this by matching on meaning instead of text. It uses vector embeddings to recognize that "Q4 revenue" and "last quarter's sales" are asking for the same thing, and serves the cached result in milliseconds instead of making another round trip to the LLM.pg_semantic_cache is a PostgreSQL extension that brings this capability directly into your database. In this post, we'll set it up from scratch in a Docker container using pgEdge Enterprise Postgres 17 and walk through working examples you can run yourself.What You'll Build
By the end of this post, you'll have:- A Docker container running pgEdge Enterprise Postgres 17 with pgvector and pg_semantic_cache.
- A working semantic cache that matches queries by meaning.
- Hands-on experience with caching and retrieval.
- A clear understanding of how semantic similarity matching works in practice.
Setting Up the Environment
For our example, we'll use a Rocky Linux 9 container with pgEdge Enterprise Postgres 17, which bundles pgvector out of the box.Dockerfile
First, we create a file called Dockerfile that defines the content of our container:Bui
[...]PGConf.DE 2026 - The schedule for PGConf.DE 2026 is now live!
Posted by Daniel Westermann in PostgreSQL Europe on 2026-02-24 at 16:45
Discover the exciting lineup of PostgreSQL speakers and exciting topics that await you on the schedule for this year.
See you in Essen in April
Create your PostgreSQL clusters with the "builtin" C collation!
Posted by Laurenz Albe in Cybertec on 2026-02-24 at 05:18

A while ago, I wrote about the index corruption that you can get after an operating system upgrade, and recently I detailed how to keep the pain of having to rebuild indexes minimal. Since this is an embarrassing problem that keeps resurfacing, here is my recommendation on how to avoid the problem entirely by using the C collation.
Management summary of PostgreSQL's collation problem
For those who cannot be bothered to follow the links above: PostgreSQL by default uses the locale support provided by external libraries, either the C library or the ICU library. One aspect of locale is the collation, the rules to compare and sort strings. Upgrading the operating system will upgrade the C and ICU libraries. Sometimes such upgrades will change the collation rules. As a consequence, indexes on string expressions may suddenly end up sorted in the wrong way, which means index corruption.
To deal with the problem, you have to rebuild affected indexes after an operating system upgrade.
Why does PostgreSQL have this problem, when other databases don't?
There are two reasons:
- Many other databases implement their own collations, so they can avoid breaking changes. When commit 5b1311acfb introduced locale support in 1997, it simply saved development effort by using an existing implementation. In retrospect, this may not have been the best decision.
- Many other databases use the C collation by default, which avoids the problem altogether. PostgreSQL takes the default value for the locale from the environment of the shell where you run
initdbto create the cluster. As a consequence, you often end up using a natural language collation with PostgreSQL.
Why are natural language collations subject to changes, while the C collation is stable?
The pleasant simplicity of the C collation
The C collation is very simple: strings are compared byte by byte, and the numerical value determines the order. That means that a simple call to memcmp() can determine the sorting order of two strings
Row Locks With Joins Can Produce Surprising Results in PostgreSQL
Posted by Haki Benita on 2026-02-23 at 22:00
Here's a database riddle: you have two tables with data connected by a foreign key. The foreign key field is set as not null and the constraint is valid and enforced. You execute a query that joins these two tables and you get no results! How is that possible? We thought it wasn't possible, but a recent incident revealed an edge case we never thought about.
In this article I show how under some circumstances row locks with joins can produce surprising results, and suggest ways to prevent it.

Image by abstrakt design
The Problem
Imagine you work in the DMV and you are in charge of managing car ownership. You have two tables:
db=# CREATE TABLE owner (
id int PRIMARY KEY,
name text NOT NULL
);
CREATE TABLE
db=# CREATE TABLE car (
id int PRIMARY KEY,
owner_id int NOT NULL,
CONSTRAINT car_owner_id_fk FOREIGN KEY (owner_id) REFERENCES owner(id)
);
CREATE TABLE
Add a car and some potential owners:
db=# INSERT INTO owner (id, name) VALUES
(1, 'haki'),
(2, 'jerry'),
(3, 'george')
RETURNING *;
id │ name
────┼───────
1 │ haki
2 │ jerry
3 | george
(3 rows)
INSERT 0 2
db=# INSERT INTO car (id, owner_id) VALUES(1, 1) RETURNING *;
id │ owner_id
────┼──────────
1 │ 1
(1 row)
INSERT 0 1
You have three owners - "haki", "jerry" and "george", and a single car with id 1 which is currently owned by "haki".
Changing Owner
[...]Top posters
Number of posts in the past two months
 Lætitia AVROT - 7
Lætitia AVROT - 7- Dave Page (pgEdge) - 6
- Cornelia Biacsics (postgres-contrib.org) - 6
- Radim Marek - 6
- Jimmy Angelakos - 5
- Zhang Chen - 4
- Hubert 'depesz' Lubaczewski - 4
- Jeremy Schneider - 4
- Robert Haas (EDB) - 4
- Vibhor Kumar - 3
Top teams
Number of posts in the past two months
- pgEdge - 13
- EDB - 10
- HexaCluster - 8
- Stormatics - 7
- postgres-contrib.org - 6
- Cybertec - 6
- Percona - 5
- Dalibo - 2
- PostgreSQL Europe - 2
- Xata - 2
Feeds
Planet
- Policy for being listed on Planet PostgreSQL.
- Add your blog to Planet PostgreSQL.
- List of all subscribed blogs.
- Manage your registration.
Contact
Get in touch with the Planet PostgreSQL administrators at planet at postgresql.org.